用户手册:采集管理
采集可以把其它网站的文章、新闻采集到自己系统里。旧系统迁移到新系统时,也可以用采集将旧系统的数据采集到新系统里。
系统自带了一些网站采集规则,但如果相关网站版面进行了改动,有可能导致无法正确采集。
原理
采集主要分析两种类型的页面:栏目列表页和文章详细页。网站的文章一般都是以栏目的方式分类,先找到要采集的栏目列表页,分析页面源代码找到其中的文章列表代码,再解析出文章的URL地址;然后分析文章详细页源代码,解析出标题、发布日期、正文等数据。
如何查看网页的HTML源代码
在浏览器的页面空白处中点击右键(不要在图片或文字上点右键),会弹出菜单(个别网站会屏蔽右键),点击菜单中的“查看页面源代码”(各浏览器的名称会稍有不同),会显示该网页HTML的源代码。
采集列表
点击后台功能导航“生成”-“采集管理”,进入采集列表页面。

采集新增
在“采集管理-列表”页面点击“新增”。

进入采集新增页面。
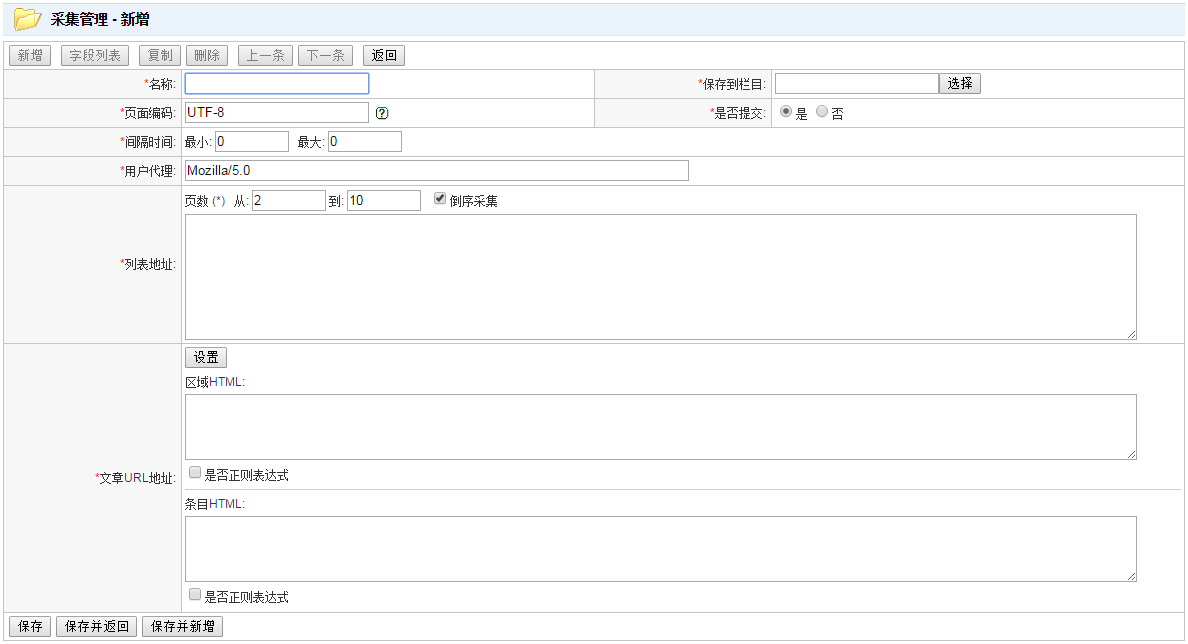
名称:采集的名称。
保存到栏目:采集的数据保存到哪个栏目。
页面编码:采集的页面的编码。通常为UTF-8或GBK。如果编码设置不正确,会出现乱码。查看要采集的页面的源代码可以确认编码格式,如:<meta http-equiv="Content-type" content="text/html; charset=utf-8" />。如果页面显示的编码为GB2312,也可以设置为GBK,因为GBK包含GB2312。
是否提交:“否”则采集到的数据为“采集”状态,需要审核后才会显示在网站上;“是”则作为采集用户提交的数据,如果采集用户拥有终审权限,采集到的数据为“已发布”状态,会直接显示在网站上。
间隔时间:采集上一条数据到下一条数据的间隔时间,取最小到最大之间的随机数。部分网站会屏蔽访问频繁的请求,在采集数据时随机间隔一段时间可以模拟正常用户浏览网站的行为。
用户代理:User Agent,模拟浏览器访问的User Agent信息,通常默认为“Mozilla/5.0”就可以。浏览器访问网站时,会带有User Agent信息,里面包含浏览器版本、操作系统版本等信息。有些网站会根据User Agent信息判断是正常用户浏览还是机器爬虫访问,如果是机器爬虫访问网站,网站有可能拒绝访问或者返回不同的页面。如果碰上此类问题,可以设置一个更像浏览器访问的User Agent。
列表地址:采集的列表页地址。可以填写多条,一行一条。可以使用占位符(*),将会被替换成“页数”,比如:http://roll.news.sina.com.cn/news/gnxw/gdxw1/index_(*).shtml,页数为2到10,则相当于http://roll.news.sina.com.cn/news/gnxw/gdxw1/index_2.shtml http://roll.news.sina.com.cn/news/gnxw/gdxw1/index_3.shtml … http://roll.news.sina.com.cn/news/gnxw/gdxw1/index_10.shtml。
倒序采集:如果页数为2到10,则从第10页开始采集。
文章URL地址:从栏目列表页中解析出文章详细页的地址。区域HTML,在列表页选定文章列表的区域;条目HTML,从区域HTML中选取文章详细页的URL地址。是否正则表达式:是否通过正则表达式匹配。
文章URL地址设置
设置好“列表地址”后,在“文章URL地址”处点击“设置”,可以进入设置页面。设置页面可以测试匹配规则,验证匹配规则是否正确。
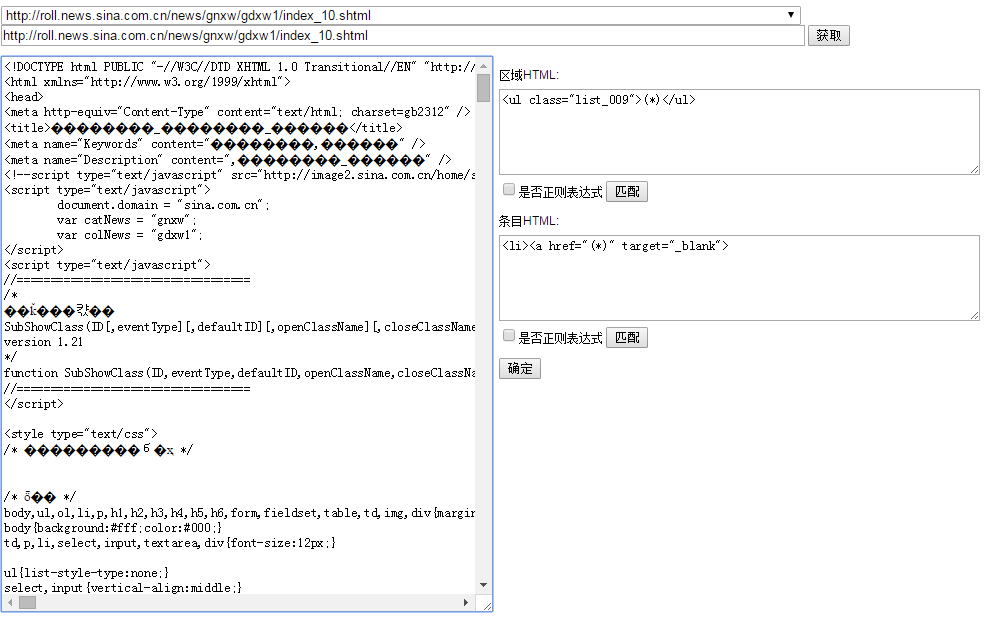
这里出现了一些乱码,这是由于新浪网的列表页编码(GB2312)和详细页编码(UTF-8)不一样导致的,因为采集的内容主要在详细页,所以采用了UTF-8作为采集的页面编码,这里并不影响采集效果。同一网站的列表页和详细页编码不一样的情况非常少见,可能正在改版,只改了一半,另一半还没来得及改。
URL地址集:顶部下拉框里显示的是采集新增页面“列表页地址”的URL地址集。如果每个列表页不完全相同时,可以选择不同的页面,以验证匹配规则是否通用。
HTML源代码:左边区域是要采集的栏目列表页的HTML源代码,点击“获取”可以重新加载当前URL地址的HTML源代码。
区域HTML:先匹配列表页的详细页列表区域。(*)是占位符,代表被匹配的内容。匹配规则对空格和换行是敏感的,利用这点可以更好的达到匹配效果。设置好匹配规则后,点击“匹配”,左侧“HTML源代码”会显示匹配结果,如果没有达到效果,可以点“获取”,修改匹配规则,重新匹配。对于复杂页面,可以勾选“是否正则表达式”,适用java正则表达式。
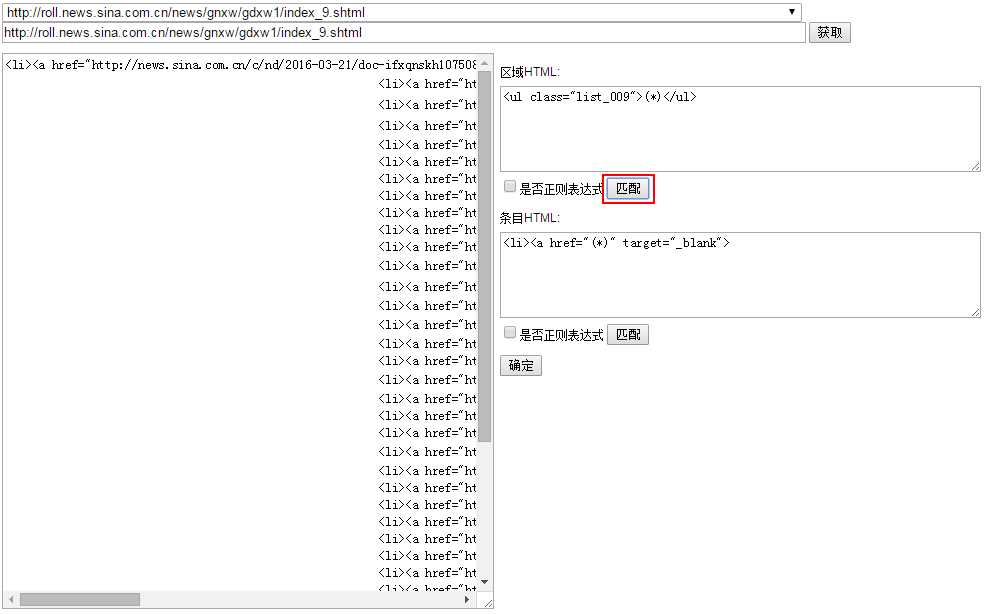
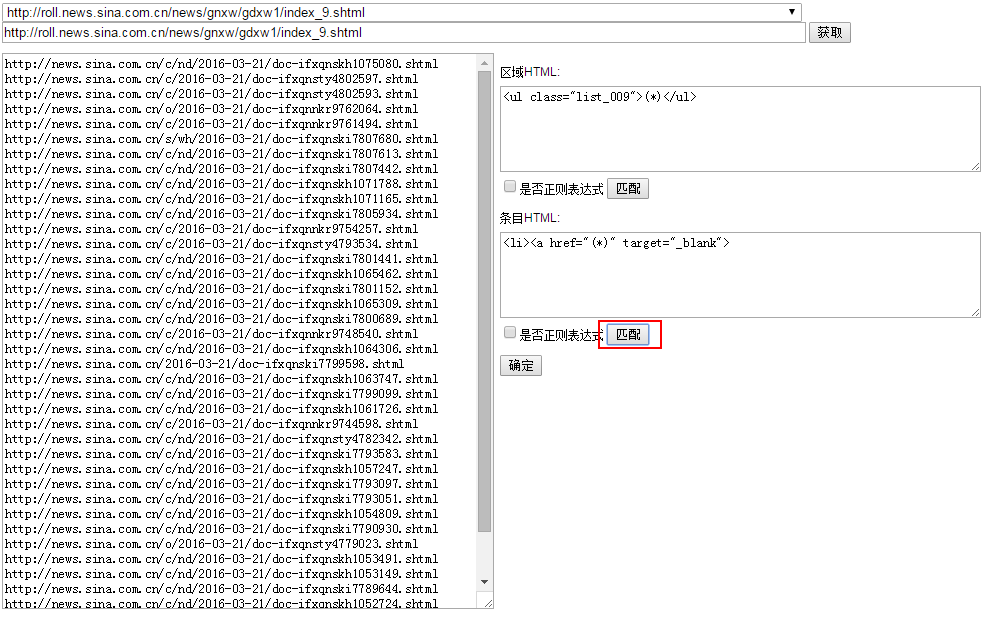
条目HTML:确定了区域HTML,点击区域HTML的“匹配”按钮,左侧“HTML源代码”显示匹配结果,然后设置条目HTML匹配规则,点击“匹配”,从区域HTML中匹配结果中,匹配详细页的URL。(*)是占位符,代表被匹配的内容。此时可以看到详细页的URL地址显示在左侧“HTML源代码”中,代表匹配规则设置成功,点击“确定”按钮,设置的内容会回写到采集新增页面。
正则表达式匹配
对于复杂的页面,占位符(*)方式可能无法达到匹配效果,这时可以使用无所不能的正则表达式。勾选“是否正则表达式”就可以开启正则表达式模式,正则表达式通过括号()匹配。
由于html中包含换行,不能直接用.匹配任意字符,而要用[\d\D]匹配任意字符。
<ul class="list_009">(*)<\/ul>改为正则表达式为<ul class="list_009">([\d\D]*?)<\/ul><li><a href="(*)" target="_blank">改为正则表达式为<li><a href="([\d\D]*?)" target="_blank">
采集字段列表
采集新增定义了要采集的列表页,并解析列表页的详细页URL地址,采集字段则是解析详细页的标题、发布日期、正文等内容。
“采集新增”保存之后,点击“字段列表”。
进入“采集字段列表”页面。此时没有设置任何字段,列表中没有数据。

采集字段新增
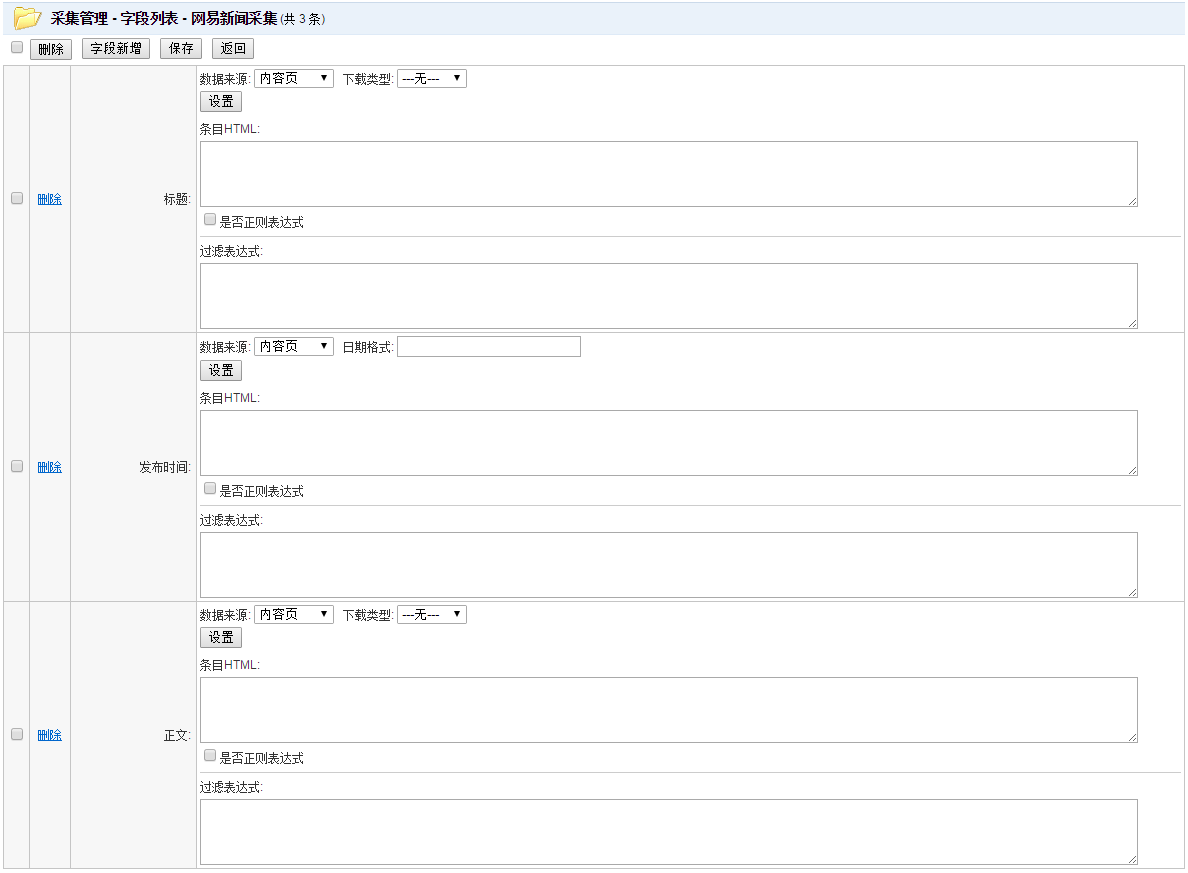
“采集管理-字段列表”页面点击“字段新增”。

进入采集字段新增页面。

这里显示的字段和文档模型相关。不必新增所有字段,常用的字段有标题、正文、发布时间。勾选需要的新增字段,点击“保存”。
采集字段设置
“发布日期”可以设置日期格式(Java的日期格式化规则),要和采集到的日期数据格式一致。如:2016-03-24 13:41:58则日期格式为yyyy-MM-dd HH:mm:ss,2016年03月24日23:14则日期格式为yyyy年MM月dd日HH:mm。
点击字段的“设置”按钮,进入设置页面。
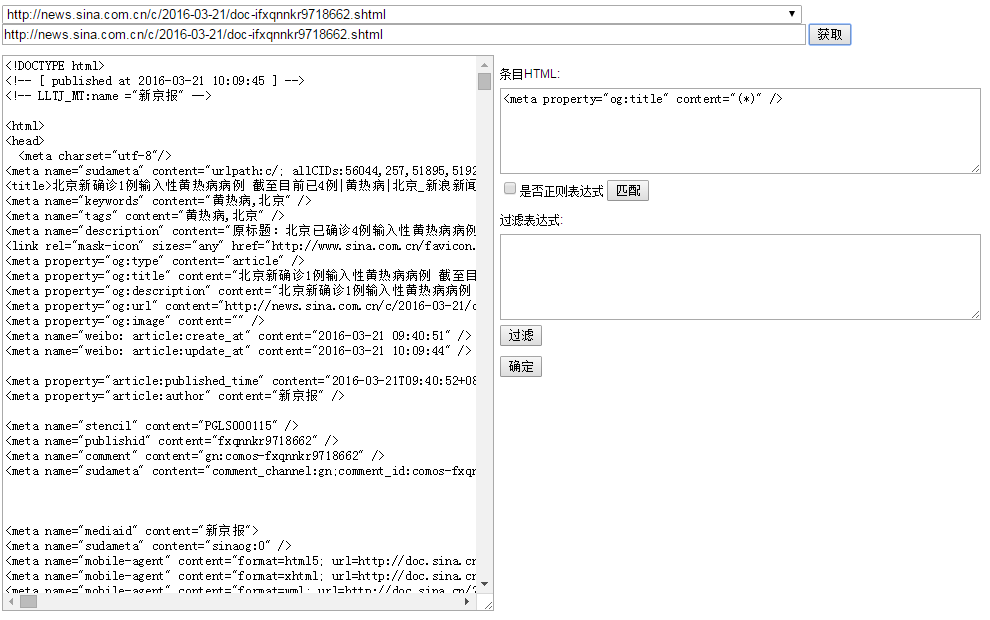
过滤表达式:支持Java正则表达式,在匹配结果的基础上,删除一些不必要的数据,比如广告之类的。
采集开始与停止
设置好采集规则并保存后,在“采集管理-列表”页面点击“开始”。采集结束后,会自动停止,如果在采集过程中,要强制停止采集,可以点击“停止”按钮。

查看采集结果
在后台“文档”管理中,可以查看到采集的结果。由于采集需要时间,采集到的数据会逐步增加,而不是瞬间采集到所有数据。
文档列表默认按发布日期排序,如果采集的数据的发布日期比较早,就有可能不会出现在文档列表的第一页,而是在后面几页。
如果采集中的“是否提交”设置为“否”,可点击“文档列表”页面的“采集”选项卡查看。
相关文章
-
2017-04-10
-
2017-05-10
-
2018-04-03
-
2018-04-01
-
2018-03-17
-
2018-04-01
-
2018-03-21
-
2018-03-26
