SQL的in、exists和join哪个性能好?结果你可能不敢信
SQL界一直以来都流传这样一种说法,不要用in,要用exists代替in,in的性能很低。甚至在程序中使用了in还会被同行嫌弃,认为在任何时候exists的性能都比in高。
小数据量这几个用起来肯定没有太多区别,而要造几百万的数据进行测试,毕竟稍显麻烦。既然所有的大神都这么说,那么就这么信吧。
现在主流的观点认为,外表比内表(子查询表)结果集大,用in效率比exists高;内表(子查询表)比外表结果集大,用exists效率比in高。但实际如何,还是看最后的测试结果吧。
静态数据
in和洪水猛兽一般,以至于静态数据都不太敢用in,要拆成or的写法。比如 where id_ in (1,2,3) 改写成 where id_ = 1 or id_ = 2 or id_ = 3。这就很奇怪了,in和or的写法虽然不同,但逻辑是一样的,怎么in就更慢呢。
后来有些贤者已经证明了,in 改成 or效果是一样的。只不过有些数据库的in有数量限制,比如oracle的in的数量最多为1000个。
准备测试数据
in在可读性、方便性上有着极大的优势,不管换成exists还是join的方式,都比不上in。心里一直想用in的渴望终于驱使自己亲自测试,性能到底有多大差距。
这里使用MySQL-5.7.32进行测试。在数据库中产生大量数据,必须用到存储过程,并且还需要一些批量处理数据的技巧。否则几百万的数据会让你处于无尽的等待中。
以下表结构来源于真实的开源java cms项目:UJCMS。
每篇文章都属于某个栏目。即可通过角色和栏目的关联,控制文章的权限;也可通过组织和栏目的关联,控制文章权限。角色、栏目和组织、栏目都是多对多关联关系。
文章表
CREATE TABLE `ujcms_article` (
`id_` int(11) NOT NULL,
`site_id_` int(11) NULL DEFAULT NULL,
`channel_id_` int(11) NULL DEFAULT NULL,
`org_id_` int(11) NULL DEFAULT NULL,
`name_` varchar(255) NULL DEFAULT NULL,
`status_` smallint(6) NULL DEFAULT 0,
PRIMARY KEY (`id_`) USING BTREE,
INDEX `idx_article_channel`(`channel_id_`) USING BTREE,
INDEX `idx_article_org`(`org_id_`) USING BTREE,
INDEX `idx_article_site`(`site_id_`) USING BTREE
) ENGINE = InnoDB;
200万条文章数据
CREATE DEFINER=`ujcms`@`%` PROCEDURE `insert_article`()
BEGIN
DECLARE i INT DEFAULT 0;
DECLARE j INT DEFAULT 1;
-- 1000条批量插入性能最好,非常重要。
DECLARE batch INT DEFAULT 1000;
SET @sql_insert = "INSERT INTO ujcms_article (id_, site_id_, channel_id_, org_id_, name_, status_) VALUES";
SET @sql_values = "";
SET autocommit = 0;
WHILE i < 2000 DO
WHILE j <= batch DO
SET @id_val = i*batch+j;
SET @channel_id = FLOOR((@id_val-1)/200) + 1;
SET @org_id = FLOOR((@id_val-1)/2224) + 1;
SET @sql_values = CONCAT(@sql_values, "(", @id_val, ",", ((@id_val-1) % 100) + 1, ",", @channel_id, ",", @org_id, ",'文章", @id_val, "',", ((@id_val-1) % 5) + 1, ")");
IF j < batch THEN
SET @sql_values = CONCAT(@sql_values, ",");
END IF;
SET j = j + 1;
END WHILE;
SET @sql_whole = CONCAT(@sql_insert, @sql_values);
PREPARE stmt FROM @sql_whole;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
-- 100个事务提交性能最好,不过效果非常细微,使用自动提交事务也基本没区别,100万数据差2-5秒,聊胜于无。
IF i > 0 AND (i+1) % 100 = 0 THEN
COMMIT;
END IF;
SET @sql_values = "";
SET j = 1;
SET i = i + 1;
END WHILE;
SET autocommit = 1;
END
栏目表
CREATE TABLE `ujcms_channel` (
`id_` int(11) NOT NULL,
`name_` varchar(255) NULL DEFAULT NULL,
PRIMARY KEY (`id_`) USING BTREE
) ENGINE = InnoDB;
1万条栏目数据
CREATE DEFINER=`ujcms`@`%` PROCEDURE `insert_channel`()
BEGIN
DECLARE i INT DEFAULT 1;
DECLARE max INT DEFAULT 10000;
SET @sql_insert = "INSERT INTO ujcms_channel VALUES ";
SET @sql_values= "";
WHILE i <= max DO
SET @sql_values = CONCAT(@sql_values, "(", i, ",", "'栏目", i, "')");
IF i < max THEN
SET @sql_values = CONCAT(@sql_values, ",");
END IF;
SET i = i + 1;
END WHILE;
SET @sql_whole = CONCAT(@sql_insert, @sql_values);
PREPARE stmt FROM @sql_whole;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
SET @sql_values = "";
END
角色表
CREATE TABLE `ujcms_role` (
`id_` int(11) NOT NULL,
`name_` varchar(255) NULL DEFAULT NULL,
PRIMARY KEY (`id_`) USING BTREE
) ENGINE = InnoDB;
9条角色数据
CREATE DEFINER=`ujcms`@`%` PROCEDURE `insert_role`()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= 9 DO
INSERT INTO ujcms_role VALUES(i, CONCAT('角色', i));
SET i = i + 1;
END WHILE;
END
角色栏目关联表
CREATE TABLE `ujcms_role_channel` (
`role_id_` int(11) NOT NULL,
`channel_id_` int(11) NOT NULL,
PRIMARY KEY (`role_id_`, `channel_id_`) USING BTREE,
INDEX `idx_rolechannel_channel`(`channel_id_`) USING BTREE
) ENGINE = InnoDB;
1.8万条角色栏目关联数据
CREATE DEFINER=`ujcms`@`%` PROCEDURE `insert_role_channel`()
BEGIN
DECLARE i INT DEFAULT 1;
DECLARE j INT DEFAULT 1;
DECLARE role_max INT DEFAULT 9;
SET @sql_insert = "INSERT INTO ujcms_role_channel VALUES ";
SET @sql_values = "";
WHILE i <= role_max DO
SET j = (i-1)*1000 + 1;
WHILE j <= i*1000 + 1000 DO
SET @sql_values = CONCAT(@sql_values, "(", i, ",", j, ")");
IF j < i*1000 + 1000 THEN
SET @sql_values = CONCAT(@sql_values, ",");
END IF;
SET j = j + 1;
END WHILE;
SET @sql_whole = CONCAT(@sql_insert, @sql_values);
PREPARE stmt FROM @sql_whole;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
SET @sql_values = "";
SET i = i + 1;
END WHILE;
END
组织表
CREATE TABLE `ujcms_org` (
`id_` int(11) NOT NULL,
`name_` varchar(255) NULL DEFAULT NULL,
PRIMARY KEY (`id_`) USING BTREE
) ENGINE = InnoDB;
900条组织数据
CREATE DEFINER=`ujcms`@`%` PROCEDURE `insert_org`()
BEGIN
DECLARE i INT DEFAULT 1;
DECLARE max INT DEFAULT 900;
SET @sql_insert = "INSERT INTO ujcms_org VALUES ";
SET @sql_values= "";
WHILE i <= max DO
SET @sql_values = CONCAT(@sql_values, "(", i, ",", "'组织", i, "')");
IF i < max THEN
SET @sql_values = CONCAT(@sql_values, ",");
END IF;
SET i = i + 1;
END WHILE;
SET @sql_whole = CONCAT(@sql_insert, @sql_values);
PREPARE stmt FROM @sql_whole;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
SET @sql_values = "";
END
组织栏目关联表
CREATE TABLE `ujcms_org_channel` (
`org_id_` int(11) NOT NULL,
`channel_id_` int(11) NOT NULL,
PRIMARY KEY (`org_id_`, `channel_id_`) USING BTREE,
INDEX `idx_orgchannel_channel`(`channel_id_`) USING BTREE
) ENGINE = InnoDB;
90.9万条组织栏目关联数据
CREATE DEFINER=`ujcms`@`%` PROCEDURE `insert_org_channel`()
BEGIN
DECLARE i INT DEFAULT 1;
DECLARE j INT DEFAULT 1;
DECLARE left_max INT DEFAULT 900;
SET @sql_insert = "INSERT INTO ujcms_org_channel VALUES ";
SET @sql_values = "";
WHILE i <= left_max DO
SET j = (i-1)*10 + 1;
WHILE j <= i*10 + 1000 DO
SET @sql_values = CONCAT(@sql_values, "(", i, ",", j, ")");
IF j < i*10 + 1000 THEN
SET @sql_values = CONCAT(@sql_values, ",");
END IF;
SET j = j + 1;
END WHILE;
SET @sql_whole = CONCAT(@sql_insert, @sql_values);
PREPARE stmt FROM @sql_whole;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
SET @sql_values = "";
SET i = i + 1;
END WHILE;
END
join查询
join可谓是最平常的解决方案了,虽然这里存在多对多关系,join后会导致数据重复,但用distinct去重就好了。
以下SQL实现,按用户所拥有的角色,查询有权限的文章列表。
SELECT
count(distinct t.id_)
FROM
ujcms_article t
JOIN ujcms_role_channel rc ON t.channel_id_ = rc.channel_id_
WHERE
rc.role_id_ in (4,6,5,1,9)

执行时间0.721秒。好像还不错,可以接受。
如果功能再复杂一些,支持通过角色和组织两个地方给权限,SQL如下:
SELECT
count(distinct t.id_)
FROM
ujcms_article t
JOIN ujcms_role_channel rc ON t.channel_id_ = rc.channel_id_
JOIN ujcms_org_channel oc ON t.channel_id_ = oc.channel_id_
WHERE
rc.role_id_ in (4,6,5,1,9) or oc.org_id_ = 233
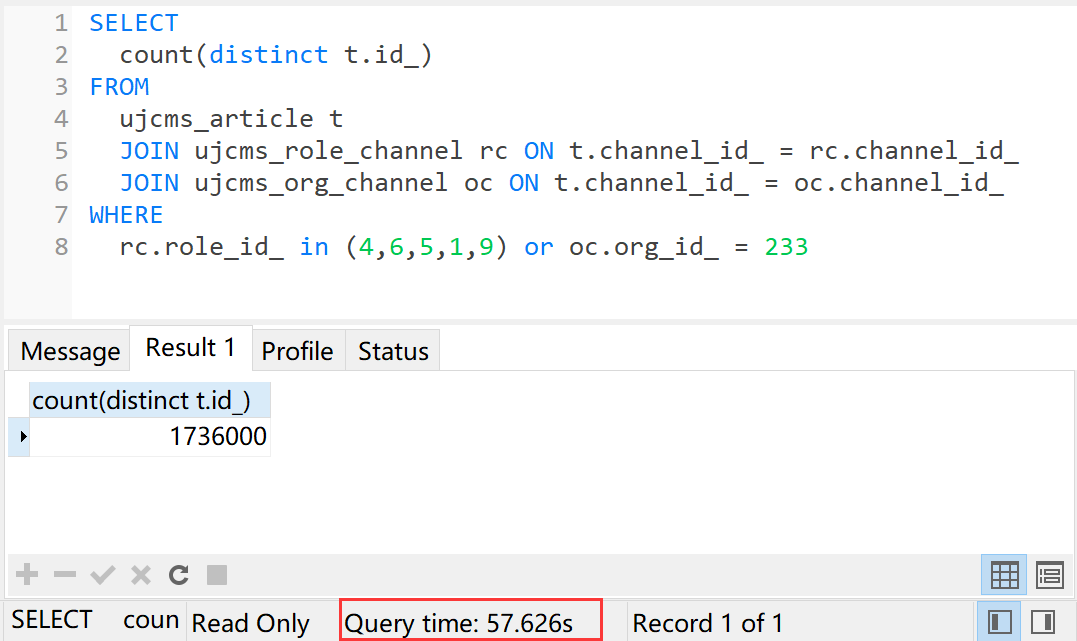
执行时间57.626秒。是的,你没有看错,将近一分钟。这就是我们不敢把功能做的太复杂的原因。
exists查询
既然join性能如此不堪,试试传说中的exists神器,会不会有奇效呢?
SELECT
count(t.id_)
FROM
ujcms_article t
WHERE
EXISTS (
SELECT *
FROM ujcms_role_channel rc
WHERE t.channel_id_ = rc.channel_id_
AND rc.role_id_ in ( 4, 6, 5, 1, 9 )
)
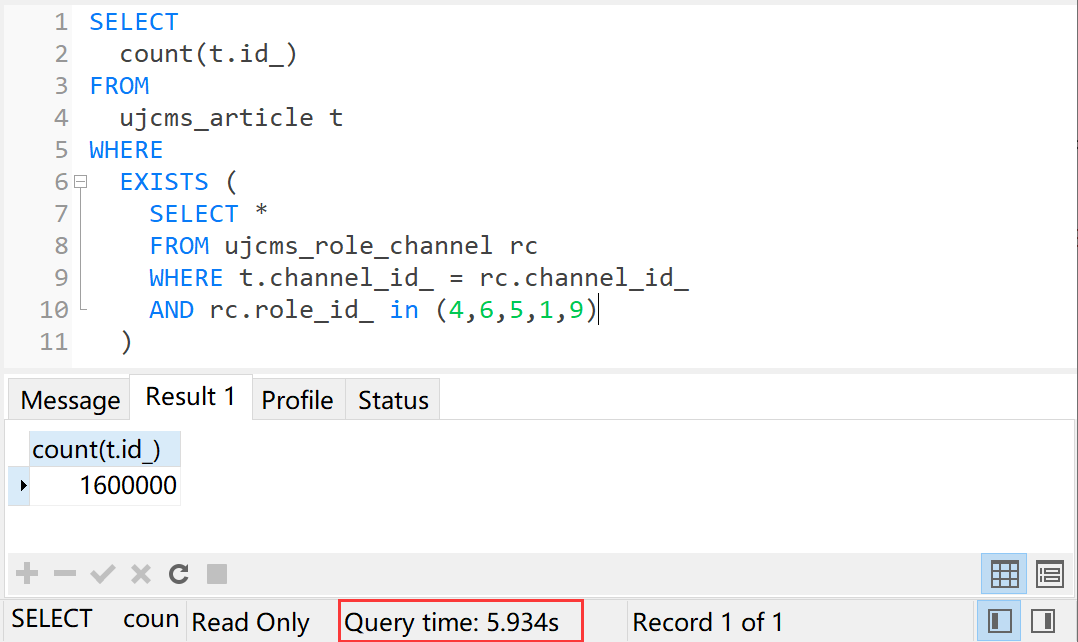
执行时间5.934秒。一个关联表就没法用了,这是神器还是神坑?
SELECT
count(t.id_)
FROM
ujcms_article t
WHERE
EXISTS (
SELECT *
FROM ujcms_role_channel rc
WHERE t.channel_id_ = rc.channel_id_
AND rc.role_id_ in (4,6,5,1,9)
)
or
EXISTS (
SELECT *
FROM ujcms_org_channel oc
WHERE t.channel_id_ = oc.channel_id_ and oc.org_id_ = 233
)
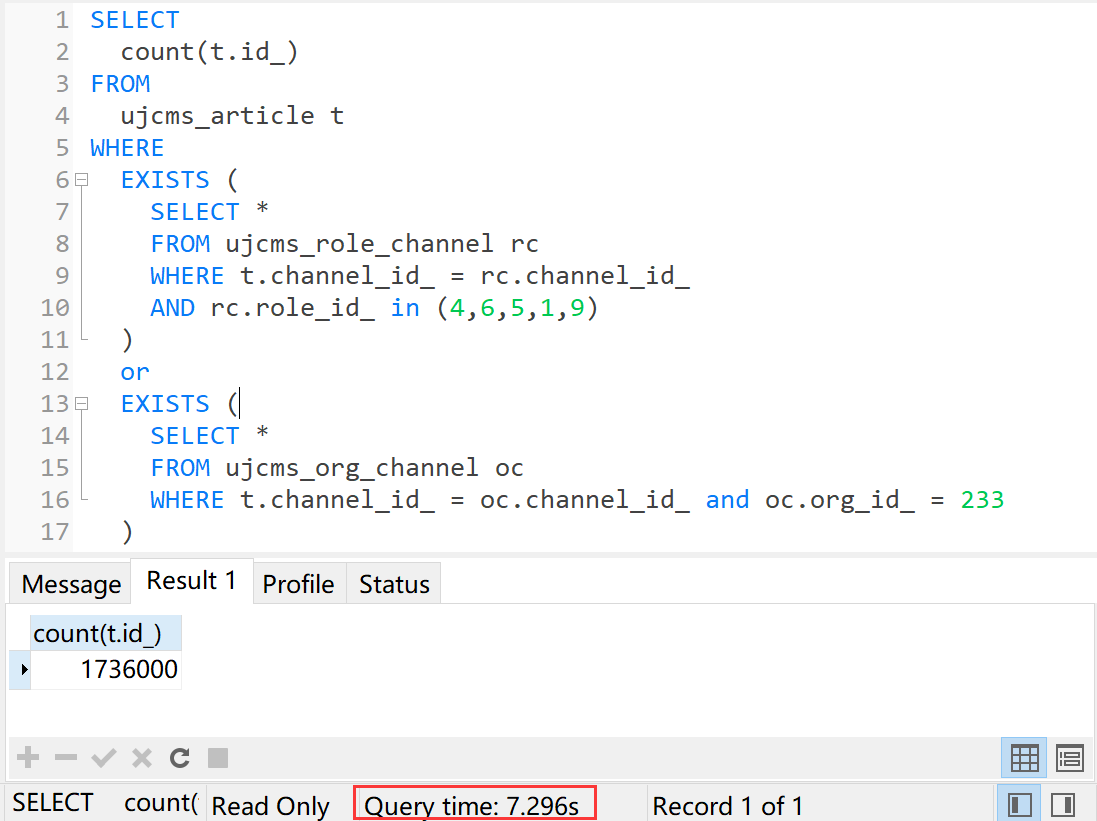
执行时间7.296秒。果然效果比join的57.626秒好太多了,只可惜7秒的时间还是太慢了。
in查询
exists神器都如此不堪,那就来好好看看臭名昭著的in是怎么出洋相的吧。
SELECT
count(t.id_)
FROM
ujcms_article t
WHERE
t.channel_id_ IN (
SELECT rc.channel_id_
FROM ujcms_role_channel rc
WHERE rc.role_id_ in (4,6,5,1,9)
)
执行时间0.275秒。这可比join的0.721秒都快的多呀。
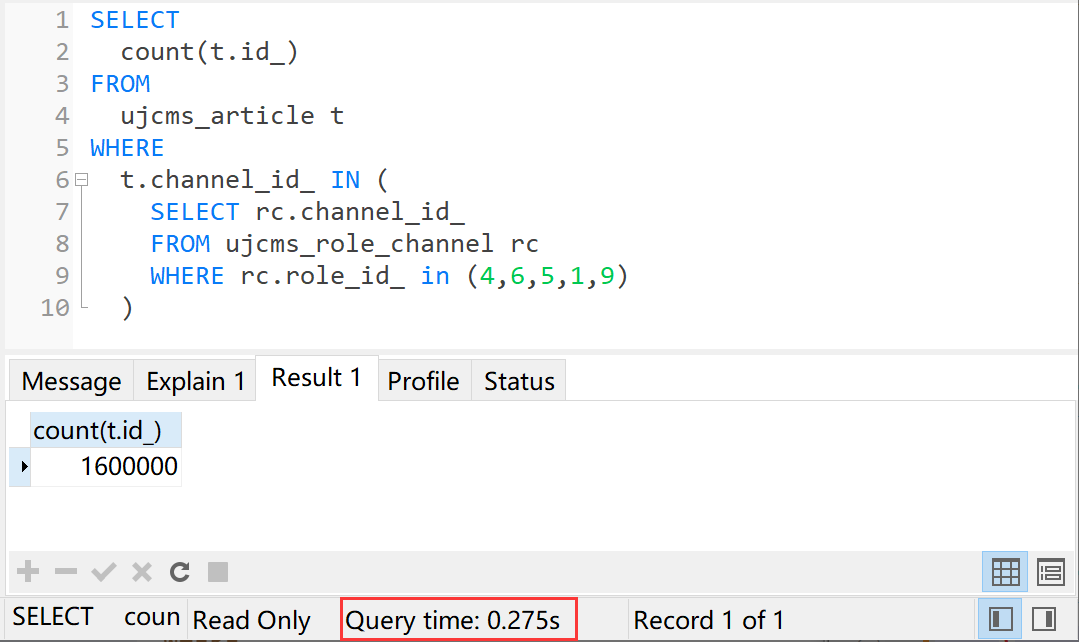
但也就比join快了几百毫秒,无关痒痛,还有两个关联表的呢,看in是怎么死的。
SELECT
count(t.id_)
FROM
ujcms_article t
WHERE
t.channel_id_ IN (
SELECT rc.channel_id_
FROM ujcms_role_channel rc
WHERE rc.role_id_ in (4,6,5,1,9)
)
or
t.channel_id_ IN (
SELECT oc.channel_id_
FROM ujcms_org_channel oc
WHERE oc.org_id_ = 233
)
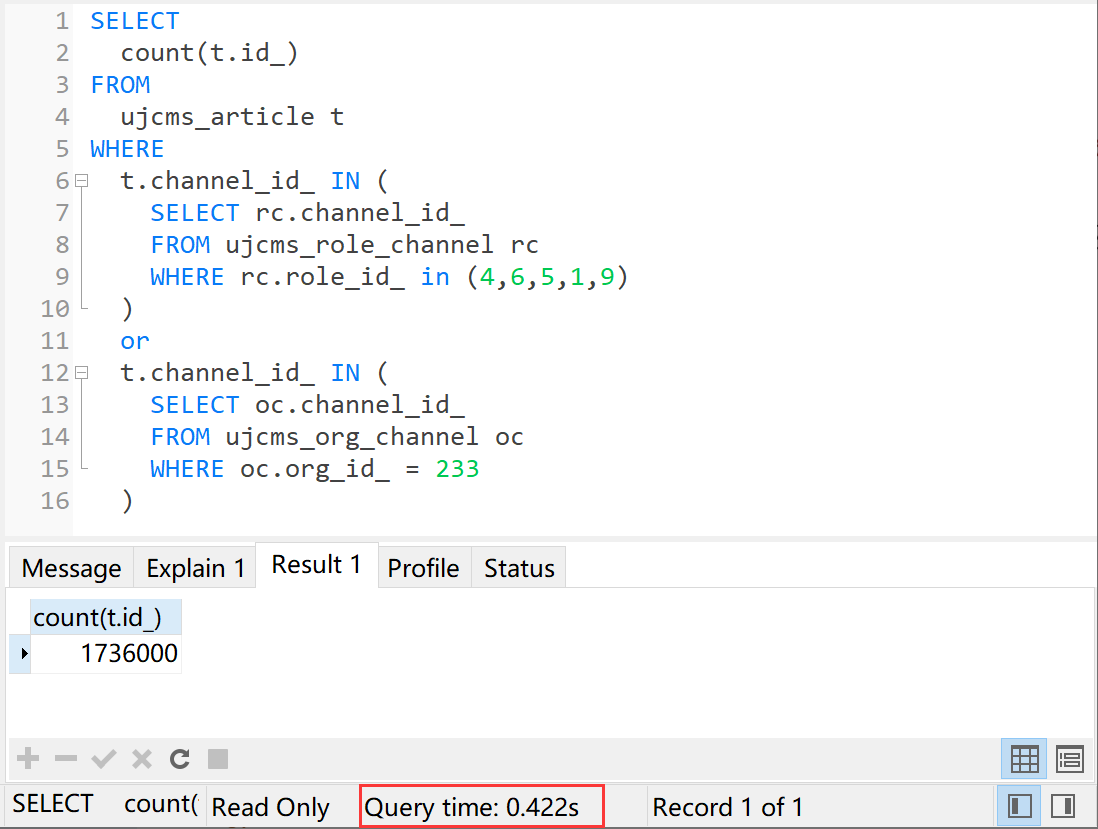
执行时间0.422秒。What?是数据大意了没有闪吗?你让join的57.626秒和exists的7.296秒情何以堪?
exists的荣光
前面说过,exists在外表数据集小,内表(子查询)数据集大的情况下,性能比in好。那么我们就来复现一下这个场景吧。
ujcms_channel表只有1万条数据,作为外表;ujcms_article表有200万数据,作为内表。
in查询
select count(t.id_) from ujcms_channel t where t.id_ in (
select a.channel_id_ from ujcms_article a where a.site_id_ in (1,3,4,5)
) and t.name_ like '栏目1%'
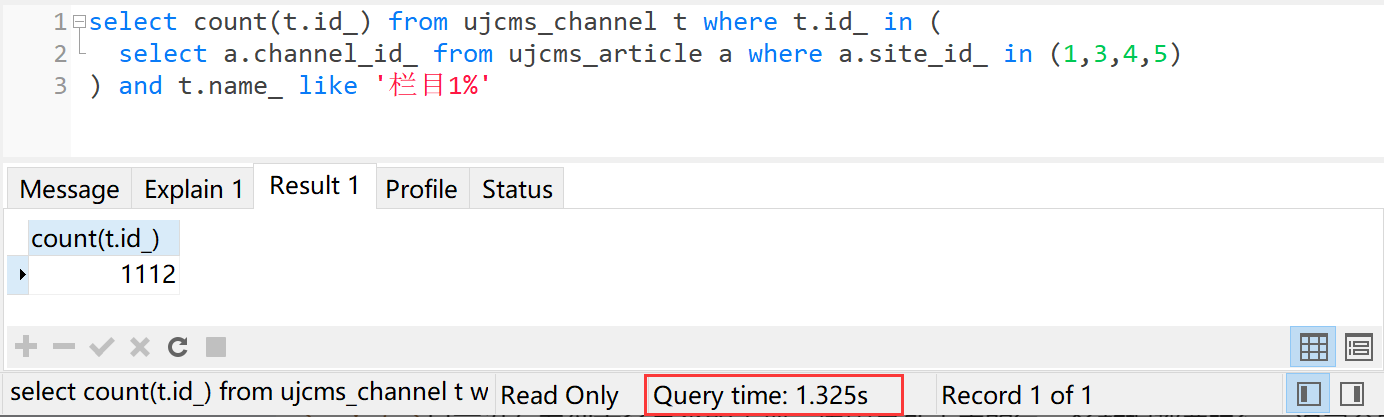
执行时间1.325秒。
exists查询
select count(t.id_) from ujcms_channel t where exists (
select * from ujcms_article a where t.id_ = a.channel_id_ and a.site_id_ in (1,3,4,5)
) and t.name_ like '栏目1%'
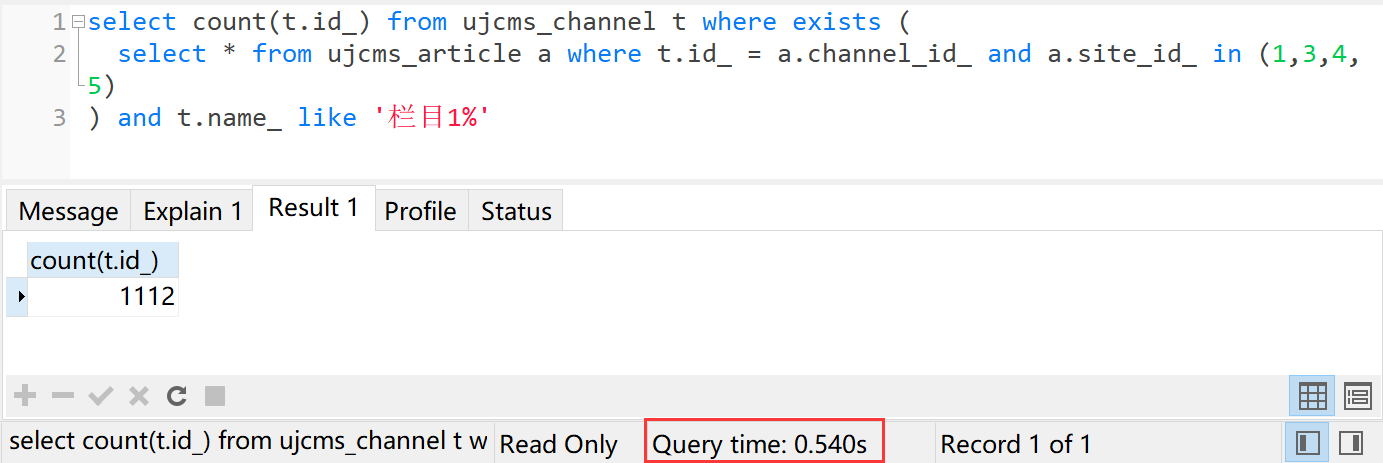
执行时间0.540秒。
join查询
select count(distinct t.id_)
from ujcms_channel t
join ujcms_article a on t.id_ = a.channel_id_
where a.site_id_ in (1,3,4,5) and t.name_ like '栏目1%'
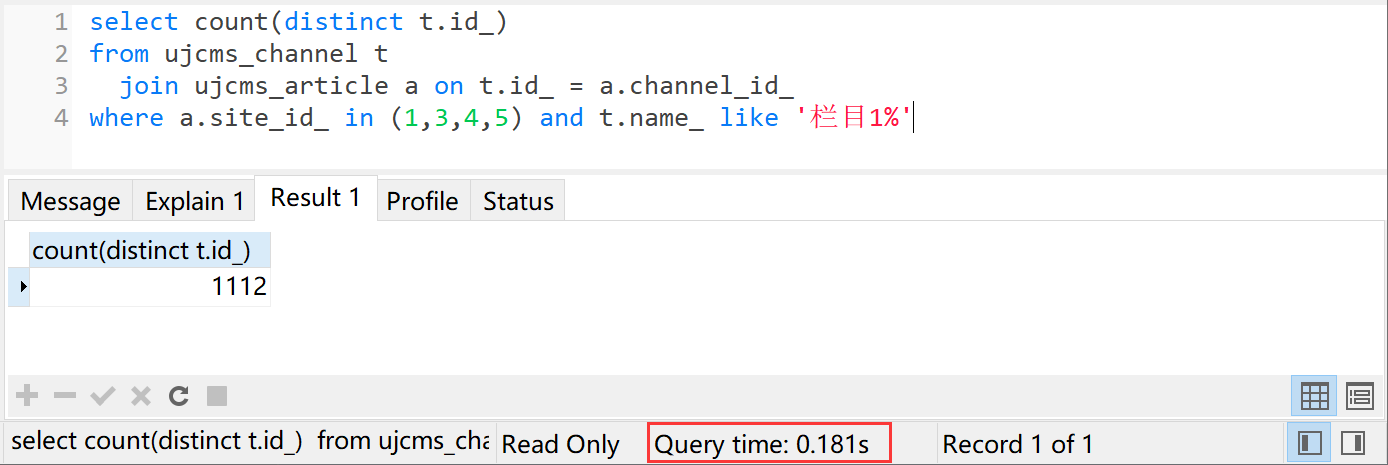
执行时间0.181秒。
可以看到in确实比exists更耗时,但join性能更好。
结论
在多对多关联时,由于会导致数据大量膨胀,用join要慎重,特别是多个多对多关联,要慎重。
exists目前没有看到太多高光的表现。原因是外表中的每一条数据都要执行一次嵌套的子查询,当外表数据量大的时候,exists的性能不可能好到哪里去。
in的子查询只需要执行一次,主要是怕这个子查询的结果集非常大,占用内存。但一般in里的子查询结果集大到离谱的情形非常少,所以in绝不是性能低下洪水猛兽,多对多关联时,大胆的,甚至尽可能的用in。
只有当外表数据量很小,而内表的数据量有十分巨大时,exists才可能有一些优势。不过通过实际测试也没发现有多大的优势。由于外表数据量非常小,而内表数据量却十分巨大的情形非常少,没有做特别严谨的测试。因此exists的使用场景非常少,实在要用,要先做好测试。
相关文章
-
2016-07-15
-
2017-07-14
-
2022-07-14
-
2023-08-12
-
2016-03-28
-
2016-08-10
-
2017-05-09
-
2016-03-24
